MoRI: Mixture of RL&IL Experts for Long-Horizon Manipulation Tasks
Introduction
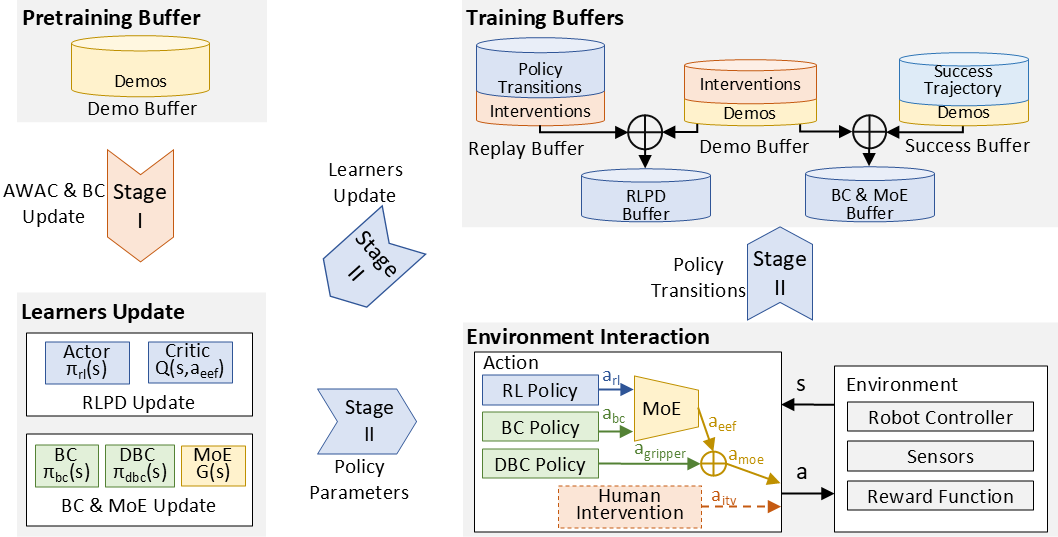
In embodied robotic manipulation, imitation learning (IL) and reinforcement learning (RL) are mainstream policy acquisition paradigms with distinct advantages: IL enables sample-efficient policy learning from human demonstrations without manual programming, while RL supports autonomous exploration in dynamic environments to outperform original demonstrations. However, IL and RL have inherent limitations and lack complementary integration: IL fails to generalize due to distribution mismatch, error accumulation, over-reliance on expert data, and poor adaptability to contact-rich fine-grained tasks, while RL faces inefficient exploration and high trial-and-error costs, partially alleviated by IL-based pre-training. To address these challenges, we propose a bionic mix-of-experts (MoE) framework that dynamically allocates high-determinism coarse motions to IL and high-uncertainty contact-rich fine manipulations to RL. In the offline phase, we independently train IL and RL modules to extract policies from limited demonstrations and stabilize value estimation; in the online phase, we continue their training and use the MoE algorithm for efficient policy selection, reducing manual intervention and accelerating task convergence. We evaluated our method on four complex real-world manipulation tasks; within 2–4 hours of online fine-tuning, it achieved a 96\% average success rate, outperforming existing supervised and reinforcement learning methods, reduced convergence time and manual intervention by 50\%, and doubled the proportion of successful training data. This work highlights the potential of integrating RL and IL via MoE to enhance robotic application performance.
Experiment
Real environment evaluation video(youtube)
Sim environment evaluation video(youtube)
Method