Abstract
Reinforcement Learning (RL) and Imitation Learning (IL) are the standard frameworks for policy acquisition in manipulation. While IL offers efficient policy derivation, it suffers from compounding errors and distribution shift. Conversely, RL facilitates autonomous exploration but is frequently hindered by low sample efficiency and the high cost of trial and error. Since existing hybrid methods often struggle with complex tasks, we introduce Mixture of RL and IL Experts (MoRI). This system dynamically switches between IL and RL experts based on the variance of expert actions to handle coarse movements and fine-grained manipulations. MoRI employs an offline pre-training stage followed by online fine-tuning to accelerate convergence. To maintain exploration safety and minimize human intervention, the system applies IL-based regularization to the RL component. Evaluation across four complex real-world tasks shows that MoRI achieves an average success rate of 97.5% within 2 to 5 hours of fine-tuning. Compared to baseline RL algorithms, MoRI reduces human intervention by 85.8% and shortens convergence time by 21%, demonstrating its capability in robotic manipulation.
Method Overview
MoRI consists of two core stages: advantage-weighted offline pre-training and MoE-driven online fine-tuning. The framework unites behavioral cloning (IL) and SAC-based RL experts, with a dedicated gating network routing expert selection based on action variance. IL handles deterministic coarse-grained movements, while RL is responsible for uncertain fine-grained contact manipulation. IL regularization further restricts RL policy within demonstration distribution, ensuring smooth expert switching and stable exploration.
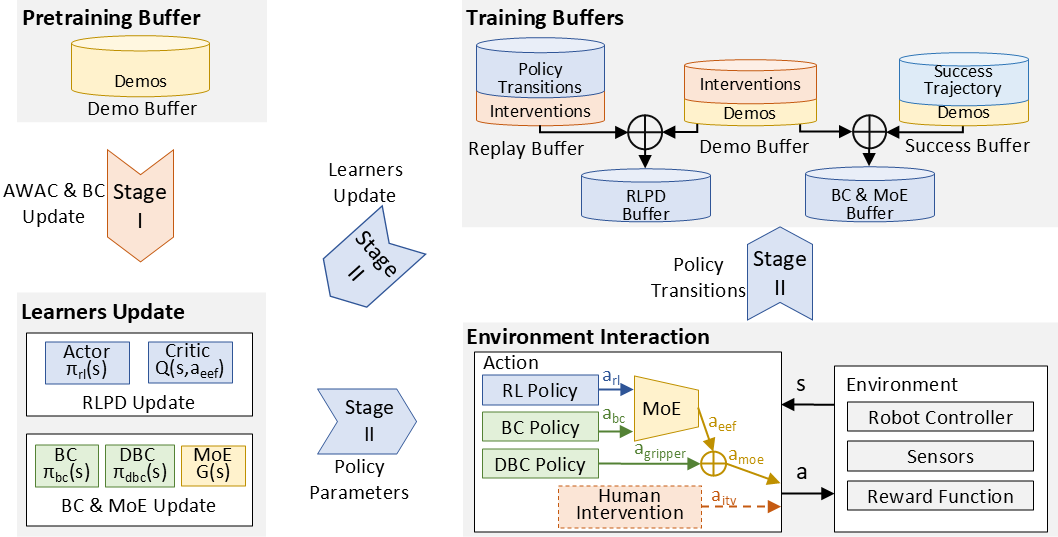
All tasks involve both coarse global motion and precise contact-rich local manipulation, with random initial pose perturbations to test generalization. The policy runs at 10Hz, implemented in JAX and trained on a single RTX 4090 GPU.
Real Environment Evaluation
Main Quantitative Comparison
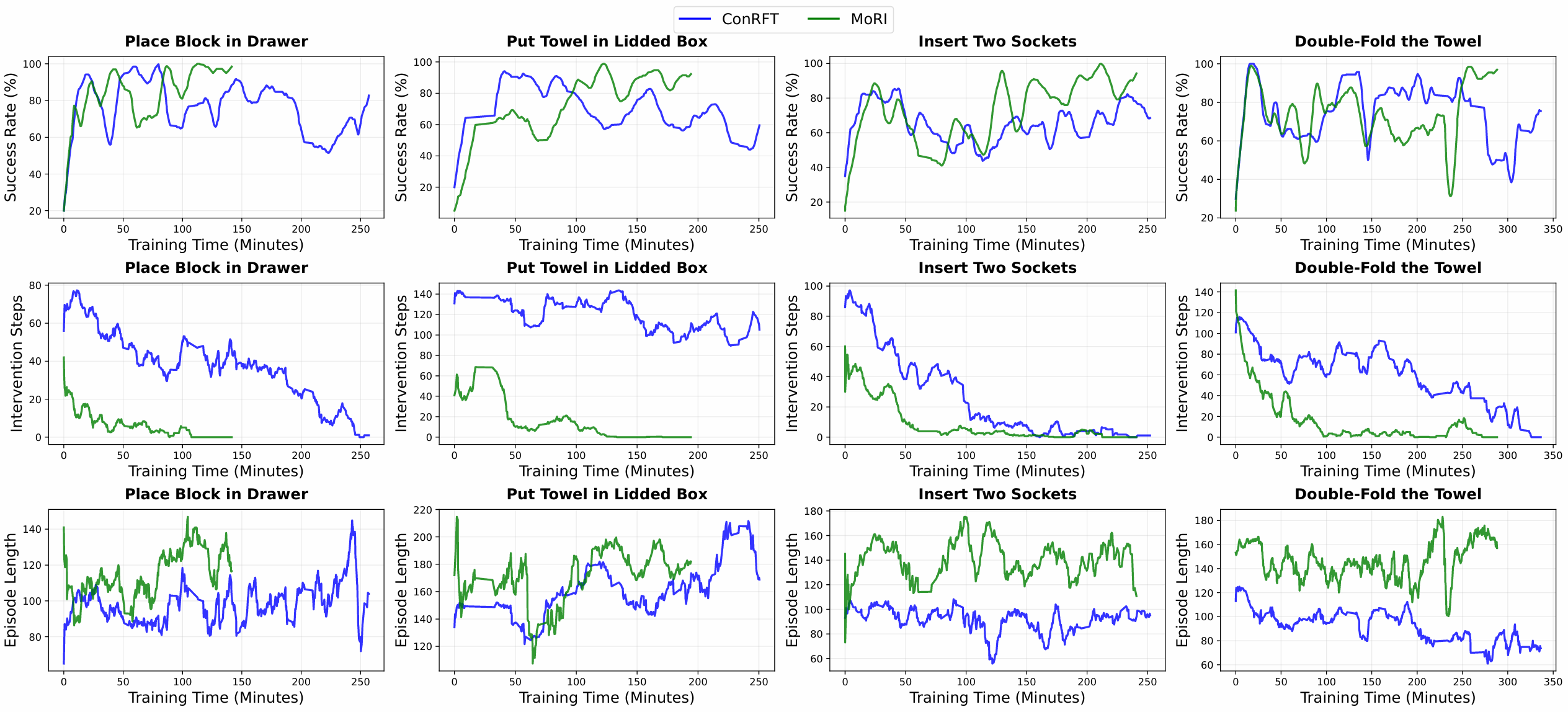
We compare MoRI against the state-of-the-art baseline ConRFT on all four real-world tasks, including training time, success rate, episode length, human intervention ratio and autonomous success ratio.
Performance Comparison: MoRI vs ConRFT
MoRI outperforms baseline ConRFT in all metrics: average success rate reaches 97.5%, convergence time is reduced by 21.0%, human intervention proportion drops from 49.6% to 7.0%, and autonomous successful trajectory ratio rises from 37.0% to 78.3%. MoRI maintains stable high performance across different manipulation difficulties, and significantly improves data efficiency and real-world deployment friendliness.
| Task | Training Time (min) | Success Rate (%) | Demo Ratio (%) | Auto-Success Ratio (%) | ||||
|---|---|---|---|---|---|---|---|---|
| ConRFT | MoRI | ConRFT | MoRI | ConRFT | MoRI | ConRFT | MoRI | |
| Place Block in Drawer | 165 | 142 | 92 | 100 | 12.8 | 5.5 | 72.3 | 85.4 |
| Put Towel in Lidded Box | 258 | 221 | 86 | 95 | 15.6 | 6.2 | 68.5 | 79.2 |
| Insert Two Sockets | 312 | 275 | 88 | 95 | 18.3 | 6.8 | 65.7 | 77.6 |
| Double-Fold the Towel | 286 | 248 | 84 | 100 | 16.9 | 5.9 | 66.2 | 81.5 |
| Average | 255.3 | 221.5 | 87.5 | 97.5 | 15.9 | 6.1 | 68.2 | 80.9 |
Ablation Study & Model Analysis
1. MoRI vs Individual BC / RL Experts
We conduct ablation to verify the necessity of MoE hybrid design by comparing MoRI with standalone BC and RL policies. MoRI achieves the highest average success rate 97.5% and the shortest average episode length, fully exceeding individual experts. It demonstrates that dynamic fusion of IL and RL can complement their respective weaknesses and adapt to task-varying motion requirements.
| Task | Success Rate (%) | Episode Length | ||||
|---|---|---|---|---|---|---|
| BC | RL | MoRI | BC | RL | MoRI | |
| Place Block in Drawer | 80 | 60 | 100 | 136.0 | 149.5 | 125.2 |
| Put Towel in Lidded Box | 60 | 75 | 95 | 254.0 | 204.1 | 169.1 |
| Insert Two Sockets | 10 | 90 | 95 | 228.0 | 201.9 | 180.2 |
| Double-Fold the Towel | 0 | 85 | 100 | — | 144.2 | 171.2 |
| Average | 37.5 | 77.5 | 97.5 | 206.0 | 174.9 | 161.4 |
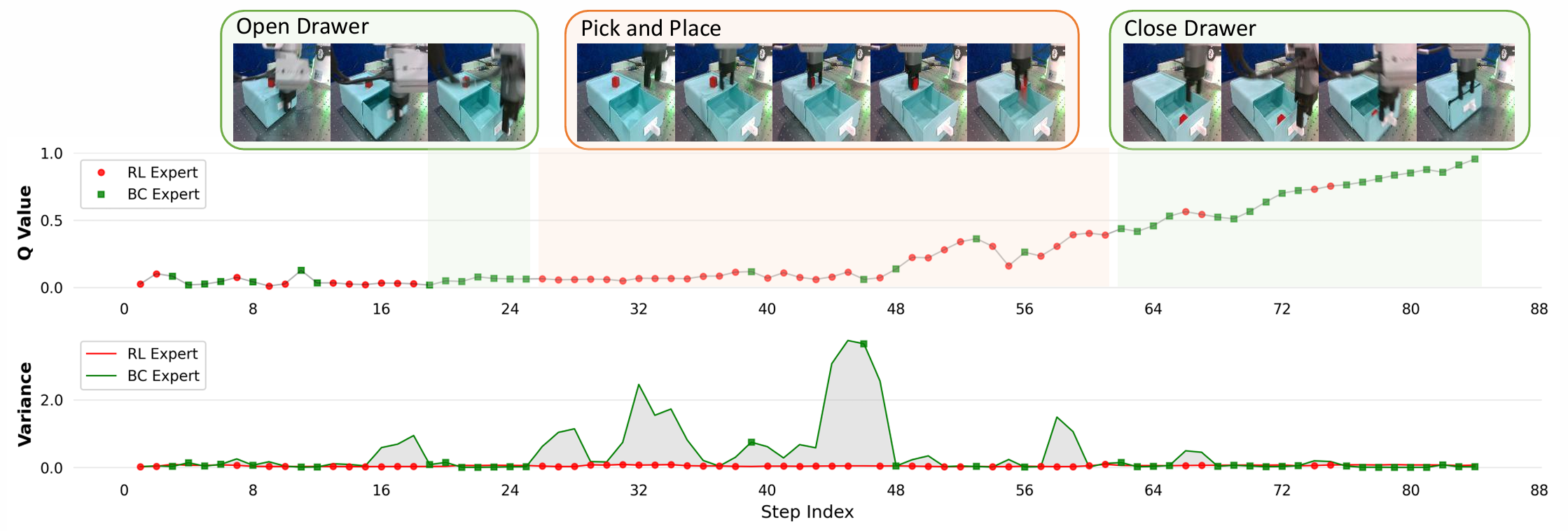
2. Expert Scheduling & Action Variance Analysis
We analyze the Q-value distribution and action variance of RL and BC experts during training. MoRI automatically assigns low-variance deterministic subtasks to BC expert (e.g., drawer opening/closing), and high-uncertainty fine contact manipulation to RL expert. With online training proceeding, the selection ratio of RL expert gradually rises from 50%–60% to 70%–80%, enabling a natural transition from conservative imitation to efficient exploratory learning.
Conclusion
This work presents MoRI, a novel Mixture-of-Experts framework that dynamically fuses IL and RL for long-horizon robotic manipulation. The offline pre-training and online fine-tuning pipeline boosts sample efficiency, while action variance-based gating and IL regularization balance exploration, stability and safety. Real-robot experiments demonstrate that MoRI achieves high success rates, faster convergence and drastically reduced human intervention. Future work will integrate vision-language models for high-level task reasoning and world models for imagination-based simulation training to further improve generalization and autonomous deployment.